Redis7–ziplist的替代者listpack
一、ziplist简介
ziplist是一种连续内存空间并且有序的压缩链表,其主要的数据结构如下图:
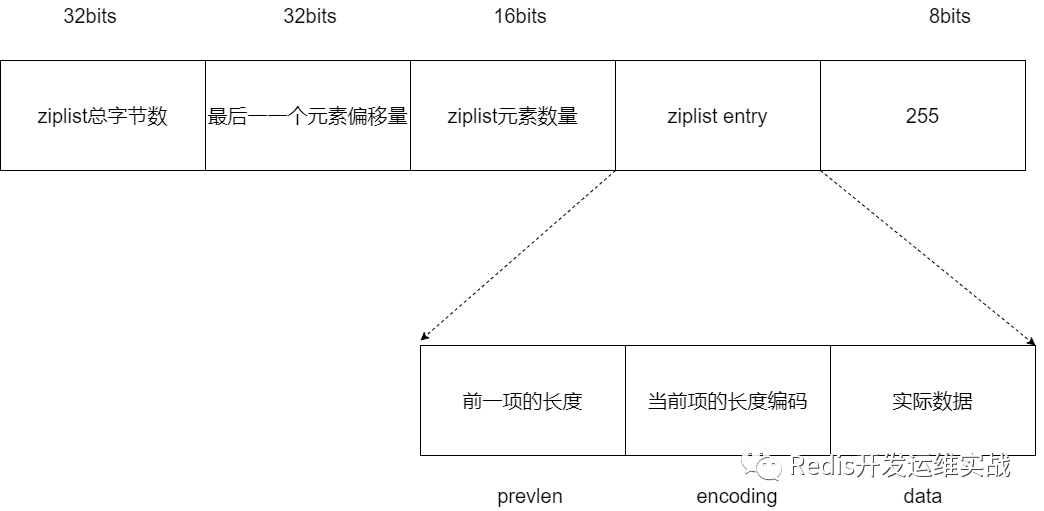
结合以上数据结构的内存模型图,我们可以看出ziplist具有的一些优势与问题:
| 优势 | 问题 |
|---|---|
| 1. 具有极高的内存利用率 | 1. 每次增/删/改需要realloc连续内存空间并进行移动 |
| 2. 连锁更新问题 | |
| 3. 查找时间复杂度过高的问题 (o(n)) | |
| 4. ziplist总内存大小限制(4G) | |
| 5. 元素个数超过65535时统计ziplist元素个数带来的遍历统计问题 |
什么时候可能会触发连锁更新呢?
向ziplist中增加、删除、修改数据内容、合并ziplist场景。
为什么会有连锁更新的问题?
从上图的数据结构中可以看到,在实际数据的内存结构前有prevlen与encoding字段,当其发生变化时可能会导致内存不连续,为了保证内存中数据的连续,所以可能会触发连锁更新。
二、listpack简介
由于ziplist存在不可避免的问题 – 连锁更新问题, 所以在Redis 5版本中,推出了ziplist替代版本listpack。
1. ziplist整体的结构与listpack的整体结构对比
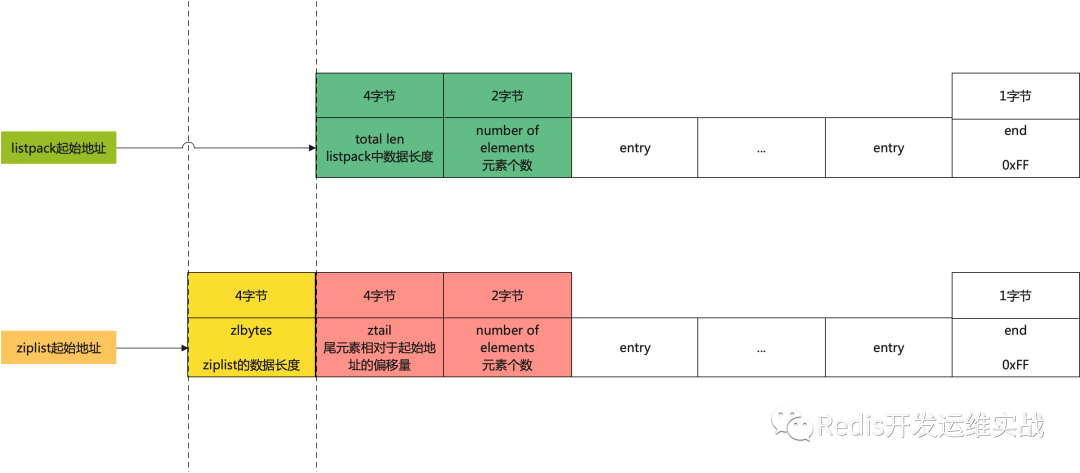
从以上整体的对比图可以看到,其实两者结构相差不大,listpack相对于ziplist,没有了指向末尾节点地址的偏移量,这样也可以解决ziplist内存长度限制的问题。
2. entry结构对比
其数据结构对比如下图:
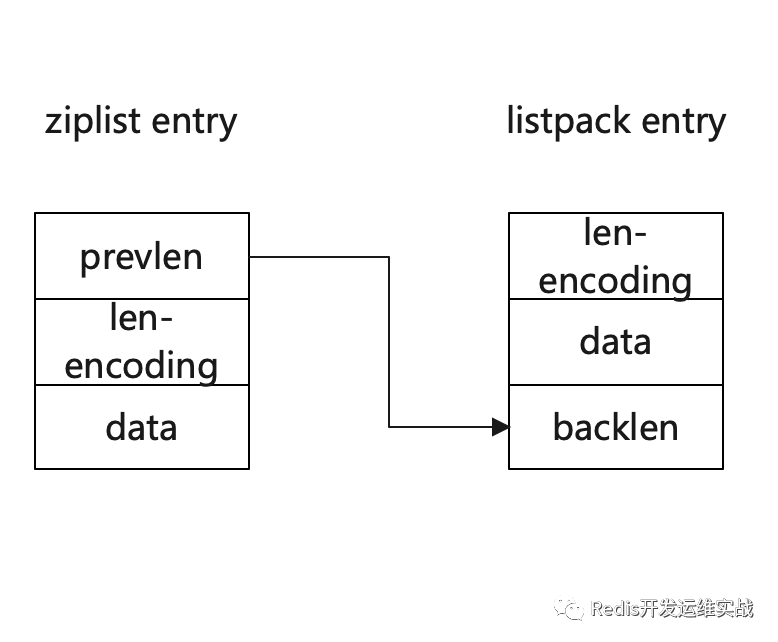
从以上结构中可以看到,listpack移除了prevlen,在data后新增了backlen,两者有着本质区别:
- 在ziplist中,prevlen代表前一个entry节点长度的偏移量;
- 在listpack中,backlen代表的是本entry节点的回朔起始地址长度的偏移量
Entry这样设计具有以下一些优势:
- 在遍历最后一个entry时可以通过lp+totallen快速定位到lp尾地址,然后使用backlen快速定位到last entry的起始地址;***并且可以将head中的last offset字段节省出来;
- 由于backlen仅代表了回朔本entry起始地址长度的偏移量,所以在增/删/改时,无需再关心前一个节点的长度,仅需要整体移动entry即可,所以不会涉及到内存的连锁更新;具体的代码流程这里不再复述;
三、listpack替换quicklist收益
1. list相关命令性能对比(quicklist with ziplist -> quicklist with listpack)
注意:以下测试结果摘自redis-pr #9740.
| command | quicklist listpack(rps) | quicklist ziplist(rps) | percentage(positive: performance enhancement, negative: performance degradation) |
|---|---|---|---|
| LPUSH | 106929 rps, p50=0.223 | 103535.75 rps, p50=0.223 | 3.2% |
| LRANGE_100 | 65737.58 rps, p50=0.375 | 67333.27 rps, p50=0.375 | -2.3% |
| LRANGE_300 | 30900.44 rps, p50=0.839 | 31346.00 rps, p50=0.823 | -1.4% |
| LRANGE_500 | 22126.59 rps, p50=1.175 | 22689.63 rps, p50=1.159 | -1.4% |
| LRANGE_600 | 19443.90 rps, p50=1.343 | 19690.08 rps, p50=1.327 | -1.2% |
| RPUSH | 109075.04 rps, p50=0.223 | 108283.71 rps, p50=0.223 | 0.7% |
| LPOP | 108636.61 rps, p50=0.223 | 110778.77 rps, p50=0.223 | 1.9% |
| RPOP | 109757.44 rps, p50=0.223 | 109206.08 rps, p50=0.223 | 0.5% |
从以上结果可以看到,lpush/rpush/lpop/rpop性能略有提升,这得益于listpack避免了连锁更新的问题,符合预期;但是lrange性能下降是因为在lpNext与lpGet函数中需要计算整个entry的长度(包括计算data长度与backlen)以及进行有效性验证,在代码逻辑上相较于ziplistNext/ziplistGet要复杂一些。
2. hash/zset类命令性能影响
由于hash与zset类命令,具有两种编码模式,默认为ziplist,在entry个数达到配置的默认值时,会将数据结构分别转换为hash与skiplist,所以在entry个数较少时,性能影响不大;entry个数越长、变更更频繁,新版本会具有更好的性能,而且在实际业务场景中,这个值都不会被配置的很大,所以这里也不再测试,仅从理论上推测性能影响。
3. 关于RDB的性能影响
由于ziplist和listpack都是一段连续的内存,所以在写入和加载上,性能不会有明显的差异。
4. RDB加载时ziplist转换为listpack时的耗时
低版本的RDB在redis7中加载时,会自动将ziplist转换为listpack,其整体加载耗时会大约增加 *9%-54%* 左右。
具体耗时结果如下:
- List(38%-46%)
注意:以下数据摘自 redis-pr #9740
| list size | quicklist length per list | quicklist ziplist loading time(second) | quicklist listpack loading and convert time(second) | convert cost time(second) | degradation percentage | rdb size | | :——– | :———————— | :————————————- | :————————————————– | :———————— | :———————— | :——- | | 250000 | 512 | 9.053 | 13.468 | 4.415 | 48.7%(memory limit reach) | 3.7G | | 250000 | 256 | 4.752 | 6.850 | 2.098 | 44.1% | 1.9G | | 250000 | 128 | 2.555 | 3.722 | 1.167 | 45.6% | 946M | | 250000 | 64 | 1.385 | 1.999 | 0.614 | 44.3% | 486M | | 500000 | 256 | 9.214 | 13.847 | 4.633 | 50.2%(memory limit reach) | 3.7G | | 500000 | 128 | 4.990 | 7.170 | 2.18 | 43.6% | 1.9G | | 500000 | 64 | 2.868 | 3.961 | 1.093 | 38.1% | 971M | | 500000 | 32 | 1.703 | 2.365 | 0.662 | 38.8% | 505M |
- hash (29%-54%)
注意:以下数据摘自 redis-pr #8887
| num of keys | entries num of one ziplist | entry size | loading time without convert(second) | rdb loading time with convert(second) | degradation percentage | | :———– | :————————- | :——— | :———————————– | :———————————— | :———————- | | 1 million | 128 | 8 bytes | 5.893 | 12.747 | 53.77% | | 1 million | 128 | 16 bytes | 7.263 | 14.727 | 50.68% | | 1 million | 128 | 24 bytes | 9.794 | 16.058 | 39.01% | | 1 million | 128 | 32 bytes | 11.636 | 18.537 | 37.23% | | 2 million | 64 | 8 bytes | 7.234 | 14.366 | 49.64% | | 2 million | 64 | 16 bytes | 8.759 | 16.478 | 46.84% | | 2 million | 64 | 24 bytes | 11.095 | 18.372 | 39.61% | | 2 million | 64 | 32 bytes | 14.413 | 20.607 | 30.06% | | 4 million | 32 | 8 bytes | 9.452 | 16.886 | 44.02% | | 4 million | 32 | 16 bytes | 10.685 | 18.975 | 43.69% | | 4 million | 32 | 24 bytes | 13.474 | 20.824 | 35.30% | | 4 million | 32 | 32 bytes | 16.041 | 22.712 | 29.37% |
- Zset (9%-16%)
注意:以下数据摘自 redis-pr #9366
| key num | zset length | loading without convert | loading with convert(after optimize) | loading with convert(before optimize) | degradation percentage | | :—— | :———- | :———————- | :———————————— | :————————————- | :——————— | | 500000 | 128 | 5.352s | 13.821 | 15.648 | 11.68% | | 500000 | 64 | 2.983s | 7.225 | 8.443 | 14.43% | | 500000 | 32 | 1.629s | 3.835 | 4.217 | 9.06% | | 1000000 | 128 | 10.977s | 27.026 | 31.965 | 15.45% | | 1000000 | 64 | 6.022s | 14.28 | 16.477 | 13.33% | | 1000000 | 32 | 3.317s | 7.522 | 8.708 | 13.62% |
四、ziplist替换为listpack后带来的连锁变更
1. 相关配置变更
* 新增list-max-listpack-size, 是list-max-ziplist-size的别名;
* 新增hash-max-listpack-entries, 是hash-max-ziplist-entries的别名;
* 新增hash-max-listpack-value, 是hash-max-ziplist-value的别名;
* 新增zset-max-listpack-entries, 是zset-max-ziplist-entries的别名;
* 新增zset-max-listpack-value, 是zset-max-ziplist-value的别名;由于新增配置均是别名,所以原有针对ziplist的相关配置,均可在redis7中自动生效,无需再做配置修改。
2. RDB相关
RDB类型新增
- RDB_TYPE_HASH_LISTPACK
- define RDB_TYPE_ZSET_LISTPACK
- define RDB_TYPE_LIST_QUICKLIST_2
版本号提升至 10
由于RDB类型和版本号的变更,所以需要更新迁移工具,解析并支持新的类型。
五、参考链接
- listpack migration – https://github.com/redis/redis/issues/8702
- replace ziplist with listpack in quicklist – https://github.com/redis/redis/pull/9740
- Replace all usage of ziplist with listpack for t_hash – https://github.com/redis/redis/pull/8887
- Replace all usage of ziplist with listpack for t_zset – https://github.com/redis/redis/pull/9366